
AI技術の急速な発展により、私たちの生活やビジネスの中で「ChatGPT」や「Gemini」などの生成AIが身近な存在になっています。
それらの基盤となっているのが「LLM(Large Language Model:大規模言語モデル)」です。
本記事では、LLMとは何か、仕組み、他のAIとの違い、そして今後の展望まで、専門的な内容をわかりやすく解説します。
LLM(大規模言語モデル)とは?
LLMとは、「大量のテキストデータを学習し、人間のように自然な文章を理解・生成できるAIモデル」のことです。代表例として、OpenAIのGPTシリーズやGoogleのGemini、AnthropicのClaudeなどが挙げられます。
LLMは「単なるチャットボット」ではなく、自然言語理解(読む)と自然言語生成(書く)を高精度に行える点が特徴です。
LLMが登場した背景
近年、インターネット上には膨大な量のテキストデータが存在しています。そのデータを学習し、文脈を理解して文章を生成できるAIを作ろうという試みが進み、ディープラーニングやトランスフォーマー(Transformer)の登場によって実現したのがLLMです。
特に、2017年に提案されたTransformer(いわゆるAttention機構)が転機となり、以降のAIモデルの進化が一気に加速しました。
生成AI・機械学習との違い
LLMと生成AIの違い
LLMは生成AIの中核的な技術です。生成AIとは、「新しいコンテンツ(文章・画像・音声など)を作り出すAI」のことを指し、その中でもテキスト生成を担うのがLLMです。
例:
- LLM → ChatGPT、Claude、Gemini(文章生成)
- 生成AI → DALL·E、Midjourney(画像生成)、Sunoなど(音声生成)
LLMと機械学習の違い
「機械学習(Machine Learning)」はデータを分析し、パターンを学ぶ技術全般を指します。LLMはその中の一分野であり、言語データを対象とした深層学習モデル(ディープラーニング)の一種です。
3つの違いが一目でわかる比較表
| 分類 | 定義 | 主な対象 | 代表例 |
|---|---|---|---|
| 機械学習 | データから規則性を学習する技術全般 | 数値・画像・文章など幅広い | 回帰/分類、レコメンドなど |
| 生成AI | 新しいコンテンツを生成するAIの総称 | 文章・画像・音声・動画 | 画像生成、音声生成、文章生成など |
| LLM | 自然言語の理解・生成に特化した大規模モデル | 文章(テキスト) | GPT、Gemini、Claude |
LLMとChatGPTとの関係性
「ChatGPT」は、OpenAIが開発したLLM(GPTシリーズ)を搭載した対話型AIサービスです。つまり、ChatGPTはLLMを活用したアプリケーションの一例であり、裏側の「頭脳」にあたるのがLLM(GPTシリーズ)です。
同じLLMでも、チャット形式だけでなく「文書要約」「文章校正」「コード生成」「データ分析補助」など、用途に応じてさまざまなサービスに組み込まれています。
その他モデルについて
Geminiについて
Googleが開発したLLM系列で、マルチモーダル(画像・音声・テキストを統合理解)に強みがあります。検索や各種Googleサービスと連携しやすい点が特徴です。
Claude / Claude Codeについて
Anthropic社が開発したモデルで、安全性・倫理性を重視して設計されています。長文処理や文書の読み取りに強みがあり、企業向けAIアシスタントとして注目されています。開発者向けに、コーディング支援に特化した提供形態(Claude Code等)も話題です。
LLMの仕組み
LLMの基本構造
LLMは以下のステップを経て、自然な文章を生成します。

トークン化
文章をAIが理解しやすい形にするための“言葉の分解作業”です。
例:
「今日は晴れです」 → 「今日」「は」「晴れ」「です」
英語なら「I love cats」→「I」「love」「cats」といった具合です。AIはこのように、文章を分割して「どんな単語(要素)が使われているか」を認識します。
ベクトル変換
次に、分けた単語を「ベクトル」という数列(数の並び)に変換します。AIは文字を直接理解できないため、“数字の世界に翻訳する”イメージです。
たとえば「猫」は [0.12, -0.45, 0.89, …] のような数の組み合わせとして扱われます。こうすることでAIは、「猫」と「犬」が似た意味を持つ単語であることを、数値の近さで理解できるようになります。
ニューラルネットワーク学習
AIの“頭脳”であるニューラルネットワークが、これらの数値をもとに単語同士の関係性を学びます。
たとえば、「空」「青い」「晴れ」などの単語がよく一緒に出てくることを学習し、「“晴れ”の周辺には“空”や“青い”が登場しやすい」と理解します。
この学習を大量のパラメータ(調整項目)を使って行うことで、AIは文脈を理解できるようになります。
文脈関係理解
AIは、今までの単語の並びから「次に来る言葉は何か?」を予測します。たとえば、「今日は空が__」まで入力されたら、AIは「晴れている」「曇っている」などを候補に挙げ、文脈的に最も自然な言葉を選びます。
これは人間が文章を読むときに「次はこう続くだろう」と感じる働きに近いものです。
デコード
最後に、AIが内部で選んだ単語を人間が読める文章として出力します。これが、私たちがChatGPTなどで見ている「AIの回答」です。
つまり、AIは トークン化 → ベクトル変換 → 学習 → 文脈理解 → 出力
というステップを短時間でこなしているのです。
精度に関わるパラメータについて
LLMの性能を左右する要素の1つが「パラメータ数」です。一般に、パラメータが増えるほど表現力が高まり、複雑な文脈理解や文章生成が得意になります。
ただし、実際の性能はパラメータ数だけで決まるわけではなく、学習データの質、学習方法、推論時の設定、追加学習(微調整)なども大きく影響します。
LLMができること・できないこと
一目でわかる:LLMの得意・不得意
| 区分 | 内容 | ポイント |
|---|---|---|
| できること | 文章生成、要約、翻訳、QA、コード支援、文書分析 | 「言語を扱う仕事」を幅広く効率化 |
| できないこと | 最新情報の完全保証、感情の本質的理解、倫理・法的責任判断 | 重要領域ほど「人間の確認」が必須 |
LLMができること
自然な文章生成(ブログ・メール・広告文など)
LLMは大量のテキストデータを学習しているため、
- テーマに沿った論理的な構成
- 文脈に即した自然な語彙選択
- トーンや文体の調整(ビジネス/カジュアル/学術など)
が自在にできます。
プログラミング支援(コード生成・バグ修正)
プログラミング支援における主な活用シーンは以下の通りです。
- 仕様書やコメントからのコード自動生成
- エラーメッセージの分析によるバグ修正提案
- 最適なアルゴリズムの提示
- テストコードやAPIリクエストの自動生成
LLMはプログラミング言語間の翻訳(例:Python → JavaScript)にも強く、異なる環境間での移行にも活用可能です。また、AIが生成したコードを理解しながら修正する「人間×AI協働開発」というスタイルも確立しつつあります。
翻訳・要約・文書分析
従来の翻訳ツールは単語や文法ベースでしたが、LLMは意味と文脈を考慮して訳すため、より自然な翻訳が可能です。さらに、LLMは以下のような高度なタスクもこなします。
- 長文レポートを要約してポイント抽出
- ビジネス文書から重要項目やリスクを分析
- 顧客アンケートの感情分析(ポジティブ・ネガティブ)
多言語ビジネスやグローバル企業では、社内文書・契約書・報告書などの多言語対応にも活用が進んでいます。
データ分析やレポート作成支援
LLMはテーブルデータや統計情報を理解し、以下のような作業を支援します。
- データ内容の要約・洞察抽出
- トレンドや異常値の検出補助
- レポート文面や可視化の生成補助
- 自然言語での質問応答(例:「10月の売上が低下した理由は?」)
特に対話型AIでは、分析結果を文章で説明する使い方が普及しています。
学習支援・質問応答(教育分野での活用)
LLMは以下のような方法で学習をサポートします。
- 難しい概念のわかりやすい説明
- クイズ作成や添削の自動化
- 英語学習・論文指導など語学・研究支援
- 学習内容に合わせた練習問題の提案
教員側にとっても、教材作成・課題生成・フィードバック支援などの業務効率化ツールとして導入が進んでいます。
LLMができないこと
最新情報の正確な把握
LLMは過去に学習したデータをもとに動作するため、リアルタイムの情報を自動で常に正しく反映できるとは限りません。
「今週の株価」や「昨日のニュース」などは誤りが混じる可能性があります。最新情報を扱う際は、Web検索や公式発表などの信頼できる情報源と併用するのが安全です。
感情や意図の本質的理解
LLMは言葉のパターンをもとに文章を生成しますが、感情や人間の意図を“感じ取る”ことはできません。そのため、「皮肉」「冗談」「暗黙の了解」などのニュアンスを誤解することがあります。
倫理・法的判断や責任の所在
LLMは法律や倫理の知識を学習していても、正義や責任を判断する能力は持ちません。医療・法務・教育などの分野で重要な決定をAIだけに任せるのは危険です。AIの回答はあくまで「参考情報」として活用し、最終判断は人間が行う必要があります。

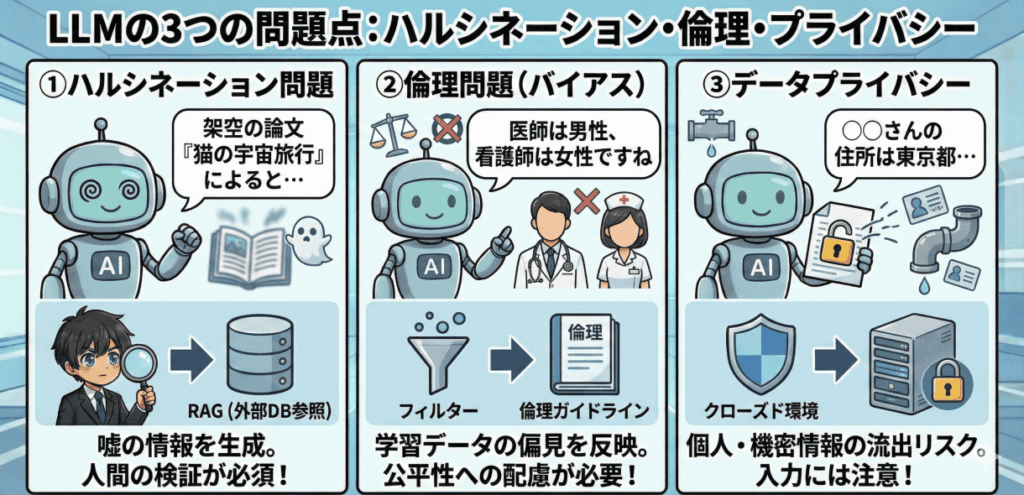
LLMの問題点
LLM(大規模言語モデル)は非常に便利で多機能なAIですが、いくつかの「課題」も存在します。ここでは、代表的な3つの問題点についてわかりやすく解説します。
代表的な課題と対策
| 問題点 | 何が起きる? | 主な対策 |
|---|---|---|
| ハルシネーション | 存在しない情報を事実のように生成する | 根拠提示、RAG、出力検証(人間チェック) |
| 倫理(バイアス) | 偏見や差別的表現が混入する可能性 | フィルタリング、運用ルール、ガイドライン整備 |
| プライバシー | 個人情報・機密情報の取り扱いリスク | 入力制限、クローズド環境、権限管理 |
問題点① ハルシネーション問題
LLMは、ときどき存在しない情報を事実のように作り出してしまうことがあります。これを「ハルシネーション(幻覚)」と呼びます。
たとえば、実際には存在しない論文や人物の名前を、あたかも本当のように生成してしまうケースがあります。これはAIが「最も自然に見える文章」を出すことを目的としているため、内容の正確さまでは保証していないことが原因です。
現在は対策として、
- 情報源を明示する
- 外部データベースを参照する(RAG:Retrieval-Augmented Generation)
といった方法が活用されています。つまり、「AIの回答=正解」ではないため、人間が検証する姿勢が重要です。
問題点② 倫理問題
LLMはインターネット上の膨大な文章を学習して作られています。そのため、元のデータに差別的な表現や偏見(バイアス)が含まれていると、AIもそれを学習してしまうことがあります。
たとえば、特定の性別・人種・職業に対する固定観念を反映した出力を行ってしまう可能性があります。これが「AIの倫理問題」と呼ばれるもので、社会的にも重要な課題です。
現在は、
- 不適切な出力を防ぐフィルタリング
- 倫理ガイドラインやAI規制の整備(各国・国際機関で進行中)
などの取り組みが進められています。
問題点③ データプライバシー
LLMの学習には大量のテキストデータが使われますが、その中に個人情報や機密情報が含まれる場合があります。そのため、AIが生成する文章に、意図せず個人情報が混ざるリスクも指摘されています。
また、ユーザーがAIに入力した内容が、モデル改善に利用される可能性があるため、企業や個人は機密情報を直接入力しないなどの運用ルールが必要です。
現在は、
- 社内専用のクローズドAI環境を導入する
- プライバシー保護に配慮したモデルや設定を活用する
といった対策が進められています。
LLMの活用事例と今後の展望
LLMは課題もありますが、それを上回るほどの活用価値があります。ここでは、実際に企業などで活用されている事例と、今後の進化の方向性を紹介します。
企業での実用例
多くの企業では、すでに業務効率化や顧客対応のためにLLMを活用しています。主な活用シーンは以下の通りです。
- 顧客対応AI(チャットボット):自然な対話で問い合わせを自動応答
- マーケティング自動化:広告文やキャッチコピーの生成・分析
- ドキュメント自動要約・ナレッジ管理:社内資料や議事録を整理
- コーディング支援(例:AIコーディング補助):コード提案やバグ修正の支援
今後の進化と社会への影響
今後のLLMは、単なるテキスト処理にとどまらず、次のような方向へ進化していくと考えられています。
- マルチモーダル化:音声・画像・動画など複数情報を同時に理解
- エージェント化:自律的にタスクを実行する「AIアシスタント」の進化
- 社会との共創:人間とAIが協力して創作・研究・意思決定を行う時代へ
つまりAIは、これから「ただのツール」ではなく、人間と一緒に考え、共に成長するパートナーとしての存在に変わっていく可能性があります。
LLMにはハルシネーション・倫理・プライバシーといった課題がありますが、これらは技術と運用の両面で改善が進められています。今後は、AIを正しく理解し、人間の判断と組み合わせることで、より安全で価値あるAI社会を築いていくことが期待されています。
よくある質問(FAQ)
Q. LLMとChatGPTは同じものですか?
A. 同じではありません。LLMは言語を理解・生成する「基盤モデル」で、ChatGPTはそのLLMを搭載した「対話サービス(アプリ)」です。
Q. LLMはなぜ間違ったことを言うのですか?
A. LLMは「もっとも自然な続きを生成する」仕組みのため、根拠の確認が不十分なまま、もっともらしい文章を作ってしまう場合があります(ハルシネーション)。重要な内容は必ず一次情報で確認しましょう。
Q. 企業で安全に使うコツは?
A. 機密情報を入力しない/権限管理を行う/人間がレビューするの3点が基本です。用途に応じてクローズド環境の導入も有効です。

